
After announcing a preview of its next-generation Azure Data Lake Storage solution at the end of June last year, Microsoft then went ahead and integrated it with Azure Databricks. Now, both it and Azure Data Explorer have been made generally available.
Azure Data Lake Storage Gen2
The goal of Gen2 - beyond ensuring the expected performance improvements - was to make Azure Data Lake Storage (ADLS) more compatible with the Apache ecosystem. Now, because ADLS is built on top of Blob Storage, a file system driver was created to achieve the aforementioned compatibility. This driver is integrated into Apache Spark and Hadoop, as well as many other commercial distributions, and the file system semantics are implemented server-side. That last point obviously reduces the complexity of the implementation client-side.
To lower the required compute operations and at the same time increase performance, a hierarchical namespace (HNS) was implemented, which supports both folder operations and atomic file operations. The latter means that a specific operation cannot be partially done - it either is completed, or it fails.
Beyond the different performance enhancements, both data at rest and in transit is TLS 1.2 encrypted, there is role-based access and thus access control lists (POSIX compliant), virtual network integration. ADLS also has storage account firewalls.
The service is tightly integrated into HDInsight, Data Factory, SQL Data Warehouse, Power BI, and others. More information about pricing and capabilities is available on the dedicated page.
Azure Data Explorer
Beyond ADLS, Microsoft also announced today the general availability of Azure Data Explorer, which it positions as a method of analyzing a large amount of streaming data in real time. This is not to be confused with Azure Analysis Services, which allows you to combine data from multiple sources into a single model so it's easier to understand.
According to the company, Azure Data Explorer (ADX) is capable of "querying 1 billion records in under a second" without needing to modify either the data or the metadata.
ADX is designed to take advantage of two services which work concomitantly: the engine, and the data management (DM) service. Both of these are deployed as virtual machines in Azure.
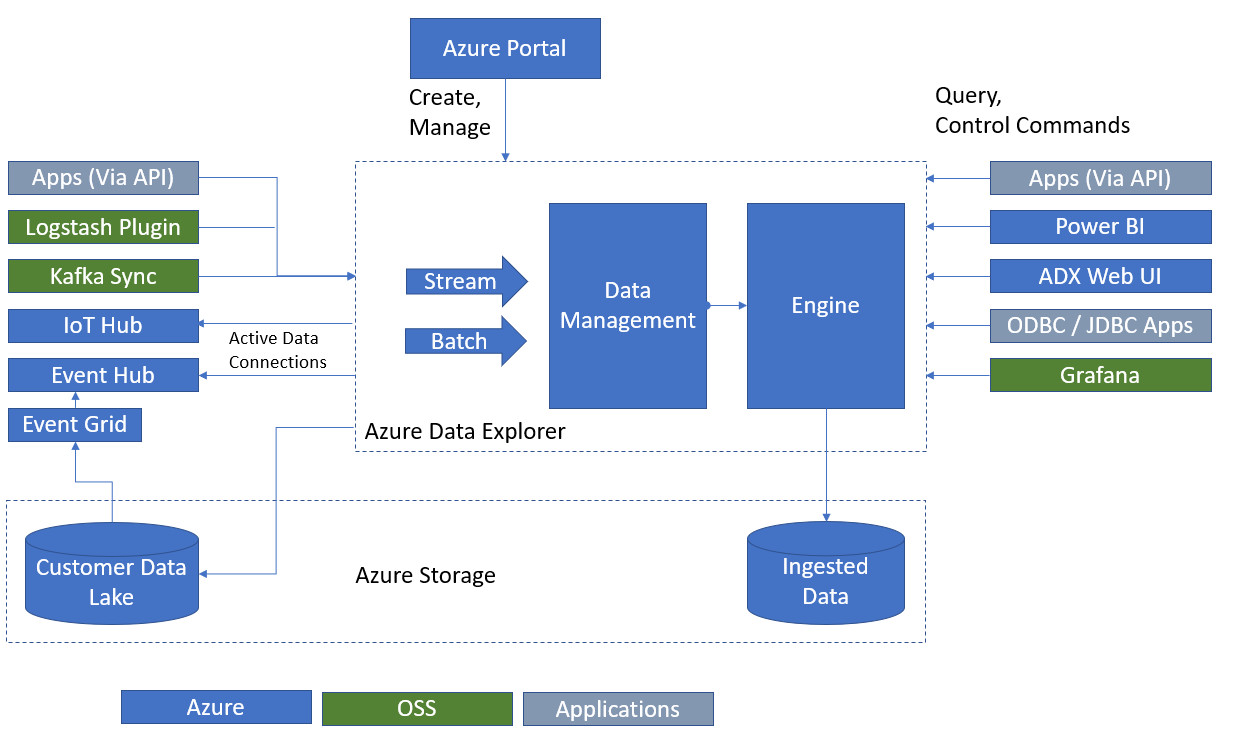
While the DM service handles raw data ingestion and related tasks, as well as failure management, the engine is in charge of processing the incoming data and serving user queries. To achieve higher performance during operation, the engine combines auto scaling and data sharding.
Azure Data Explorer is available in 41 Azure regions, which don't include West Central US, Germany, or US Gov Iowa.
Azure Data Factory Mapping Data Flow (Preview)
To go along with the services above which have reached GA status, a preview for Mapping Data Flow within Azure Data Factory was made available. For context, Data Factory is a service which allows hybrid data integration from a variety of sources. In other words, folks can move data from various on-premises locations and take advantage of the scalability of the cloud when managing said data.
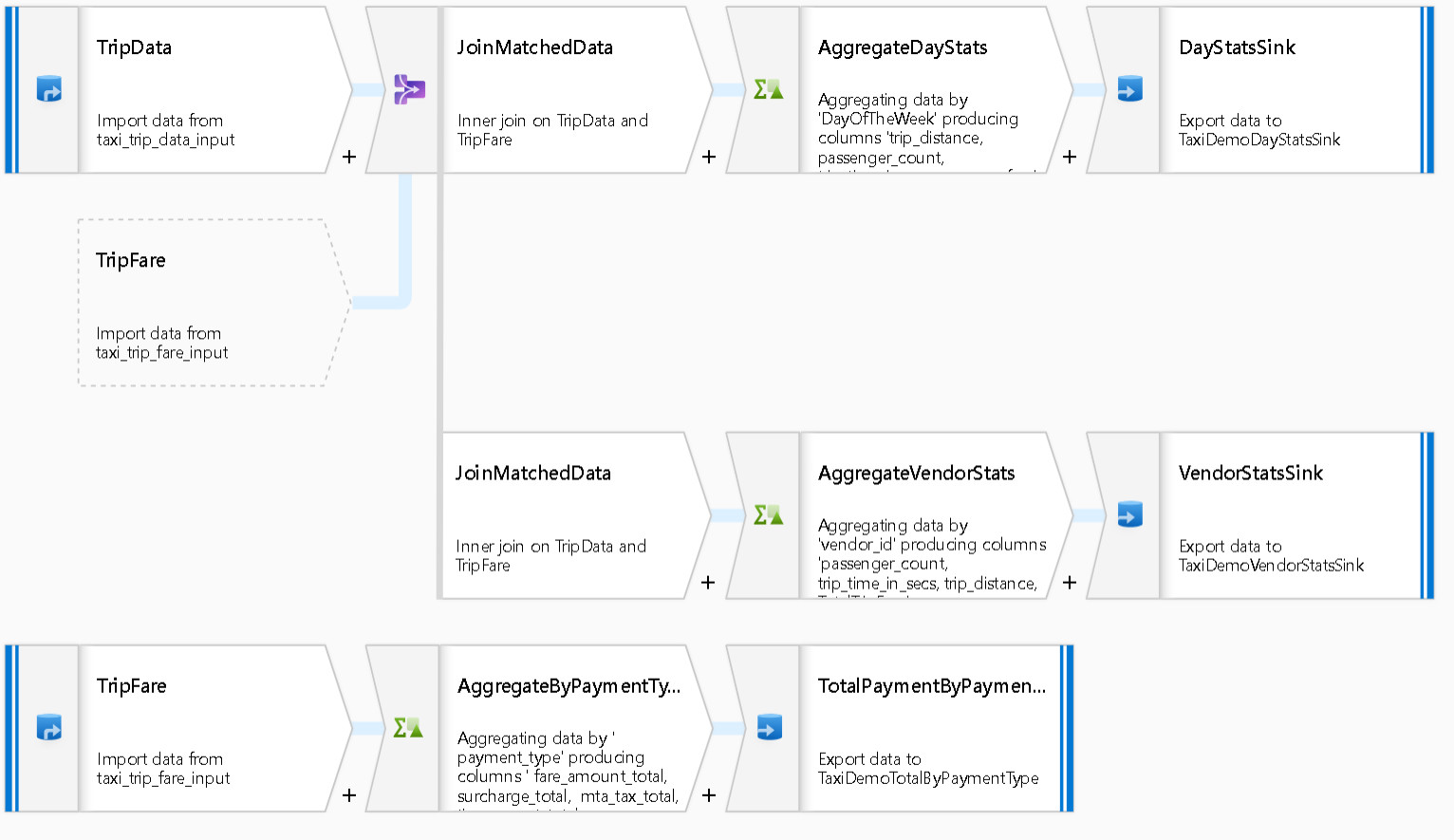
As per Microsoft's description, via Mapping Data Flow, folks are able to:
[...] visually design, build, and manage data transformation processes without learning Spark or having a deep understanding of their distributed infrastructure.
Azure Data Factory is available in 21 Azure regions, with expansions in East Asia, Australia East and others, planned in future. Folks interested in checking up the preview can sign up here.














